


为什么存在字节对齐的问题
CPU内部有几个重要的部件决定了CPU一次能处理的字节和可访问的内存大小。寄存器,ALU和数据总线的位数,这些共同决定了CPU的字长,常见CPU的字长有4位,8位,16位,32位和64位。字长越多,则CPU内部硬件规模和造价越高。
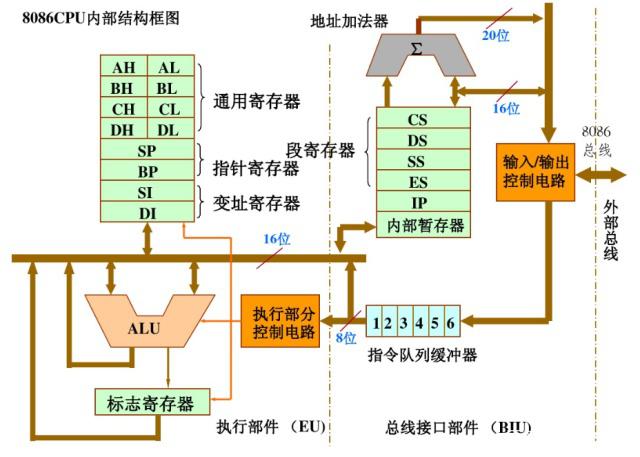 8086内部框图
8086内部框图
例如,经典的8086CPU字长就是16位。它的寄存器和总线也是16位。那么它一次处理的数据长度就为2字节。编程新手常常不能理解这一点。认为CPU就是按一个个字节处理数据的。但实际上CPU是按字长来处理数据的。
明白了CPU按什么粒度来处理数据,我们再来看看地址访问问题。
当8086访问一个整字(16位)变量时,CPU把需要访问的地址放入地址总线,把控制总线置为读入操作. 内存子系统根据地址总线选定内存 单元, 检查控制总线发现是读入操作, 则读取内存单元中的数据, 写入数据总线。
关键的地方是,不论是访问奇地址还是偶地址,CPU总会把偶地址放到总线上。
访问一个变量时,当该变量的地址为偶地址(即字变量的低字节在偶地址单元,高字节在奇地址单元),则8086将用一个总线周期访问该字变量;如果该字变量的地址为奇地址(即字变量的低字节在奇地址单元,高字节在偶地址单元),则8086要用两个连续的总线周期才能访问该字变量,每个周期访问一个字节。
到此为止我们知道了字节对齐的一个好处,就是访问的效率提高了。
接下来我们来谈谈奇地址访问问题
8086属于CISC复杂指令集,它代表着指令复杂、体积庞大,晶体管耗费多。后来科学家们就提出了一种更为简单的指令集,叫做精简指令集,全称是Reduced Instruction Set Computing,简写为RISC。
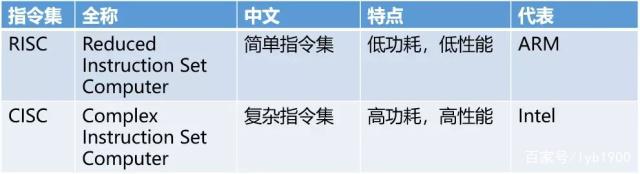 RISC与CISC
RISC与CISC
这类CPU代表就是ARM,MIPS。它们在精简指令集的同时,也去除了CPU内部对于访问奇地址支持。因为要完成奇地址内容的访问实现太复杂,要做两次访问,并做内容移位和合并的操作。这样会浪费有限的晶体管。
我们不能奢望,我们的程序跑在支持奇地址的CPU上。
评论区